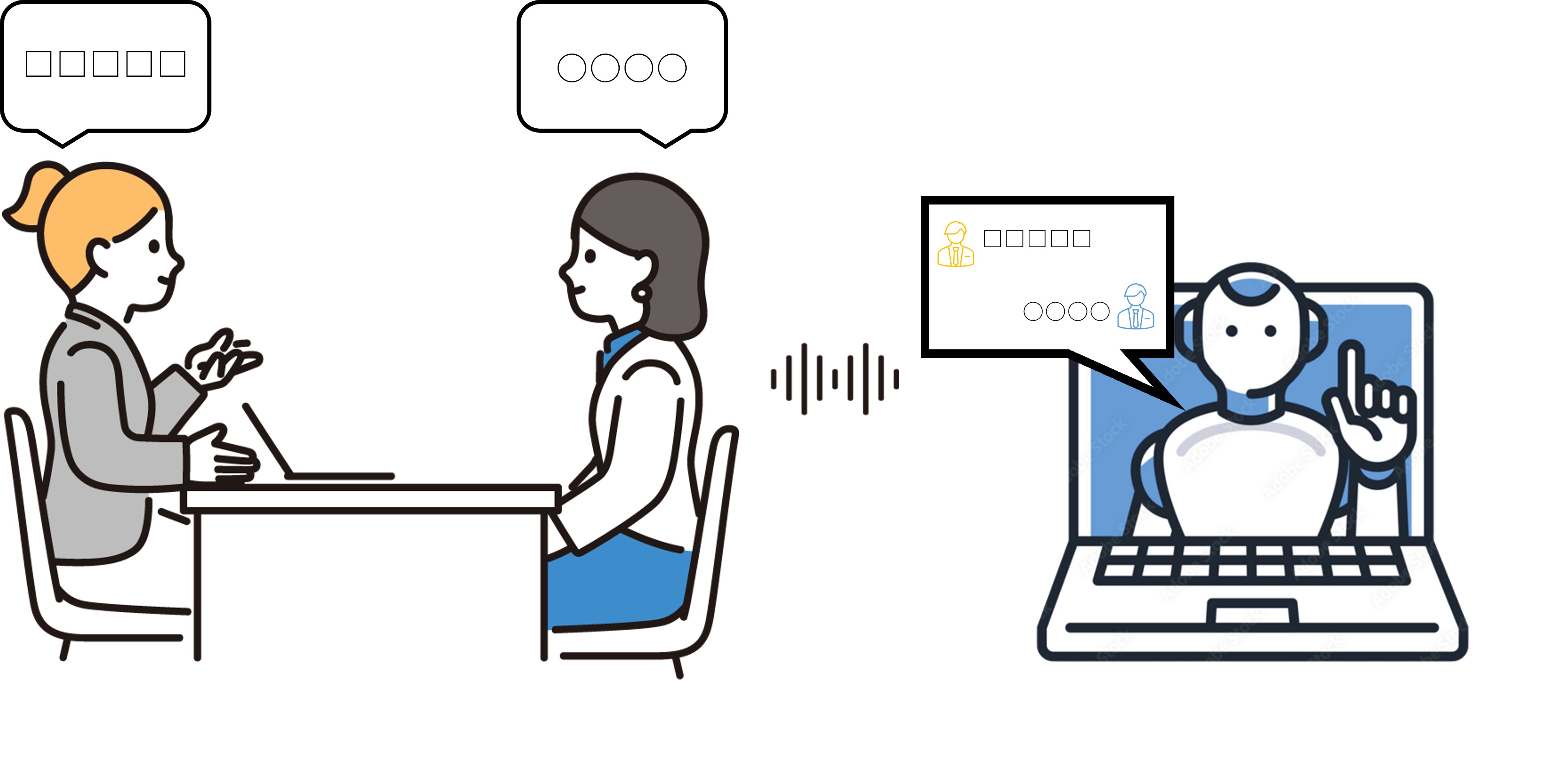
こんにちは。レスターエンベデッドソリューションズ テクノロジーデザイン本部です。
前編ではマイクから入力された音声部分を録音するところまで記事にしましたが、今回はその続きで前回ファイルに保存したWaveデータをWhisperを用いて文字起こしを行うところを記事にしたいと思います。
Jetson Generative AI Lab
Jetson Generative AI LabはNVIDIA社が公開しているウェブサイトにて、JETSONを用いた様々な生成AIのチュートリアルが用意してあり、生成AIのデモアプリケーションが動かす事ができるようになっています。
この中にはWhisperも含まれており、今回はこのデモアプリケーションの環境を用いて文字起こしを行おうと思います。
Docker 環境
NVIDIA社はさまざまなAI/MLのDockerのコンテナビルド環境を用意してあり,デモアプリケーションもこれらのコンテナ上で動作しています。
また一部ビルド済みのコンテナはDocker Hub上に公開されていますので、コンテナイメージをダウンロードするだけで動作環境が整い、いろいろなモジュールのインストール作業の必要なく手軽に環境が構築できます。
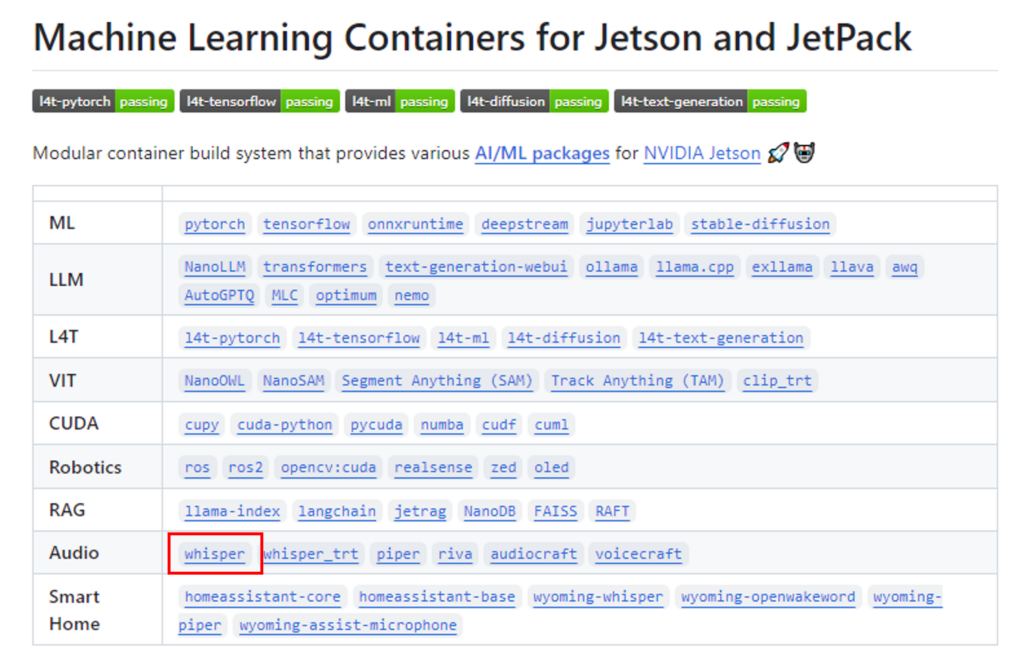
Whisperのコンテナも用意されているので、今回はこのコンテナを用いて文字起こしを行います。
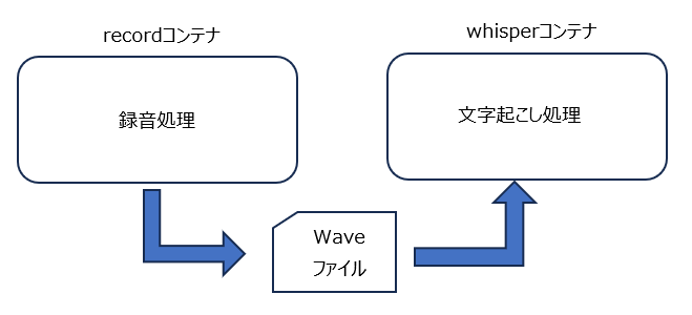
作成するコンテナの環境ですが文字起こしの部分をわかりやすくする為に、以下のように前回作成した録音処理をそのままにし、文字起こし処理を新たに作成しそれぞれ別のコンテナで動かしてみます。
docker-compose.yaml は以下のようにしています。
services:
container1:
runtime: nvidia
image: record:latest
container_name: record
volumes:
– /home/isk/ISK/Container/blog/Src/Record:/src
– /home/isk/ISK/Container/blog/Data/Wav:/wave
devices:
– “/dev/snd:/dev/snd”
– “/dev/bus/usb:/dev/bus/usb”
environment:
– NVIDIA_VISIBLE_DEVICES=all
working_dir: /src
tty: true
command: python3 main.py
container2:
runtime: nvidia
image: dustynv/whisper:r36.2.0
container_name: whisper
volumes:
– /home/isk/ISK/Container/blog/Src/Whisper:/src
– /home/isk/ISK/Container/blog/Data/Model:/data
– /home/isk/ISK/Container/blog/Data/Wav:/wave
working_dir: /src
environment:
– NVIDIA_VISIBLE_DEVICES=all
tty: true
command: bash
container1が録音処理を動かすコンテナです。
コンテナイメージはWhisperのコンテナをベースにpyaudioなど録音に必要なモジュールを付加して作成したコンテナイメージを使用しています。
またコンテナ上からUSBマイクが使用できるようにdevicesの設定もしています。
container2が文字起こし処理を動かすコンテナです。
コンテナイメージはNVIDIA社が用意しているコンテナイメージをそのまま使用しています。
それぞれホスト上にあるソースの格納場所と waveファイルの格納場所をマウントして、container1の録音処理で出力したwaveファイルを、container2の文字起こし処理で読み出せるようにしています。
文字起こし処理
以下がcontainer2で動かす、文字起こしのソースです。所定のフォルダ内のwaveファイルの文字起こしを実施していきます。
import sys
import os
import wave
import whisper
source_folder = “../wave”
print( “model load start” )
model = whisper.load_model(“large”,download_root=‘../data’ )
print( “model load end “ )
def main():
try:
while True:
# 指定フォルダ内のファイル一覧を取得し、更新日時でソート
files = os.listdir(source_folder)
files.sort(key=lambda x: os.path.getmtime(os.path.join(source_folder, x)))
# .wavファイル毎に文字起こしを実施
for file in files:
if file.endswith(“.wav”):
source_file = os.path.join(source_folder, file)
#文字起こしを実施
result = model.transcribe(source_file, language=‘ja’)
# 文字起こし結果表示
print(result[‘text’])
# 文字起こしが完了したファイルを削除
os.remove(source_file)
except Exception as e:
print(“例外発生:”, e.args)
pass
if __name__ == __’main__‘:
main()
どうでしょうか?
文字起こしの部分だけをみれば” whisper.load_model”でモデルをロードして“model.transcribe”で実施するだけです。たったこれでだけで音声から文字起こしができてしまいます。どちらかといえば前回の音声を録音する方が大変です。
処理結果
実際に文字起こしをしてみようと思います。作成したソフトはprint文でコンソールに出力しているだけですので、以下のコマンドを用いて起動したコンテナにログインして動かします。
docker exec -it whisper bash
ログインした後、前述のプログラムを動かしてみました。今回はYouTubeに上がっているニュースの動画を文字起こししてみました。
root@f86dc8a90923:/src# python3 main.py
model load start
model load end
アメリカの景気が後退するという懸念から、マーケットでは午後に入り株安と円高がさらに加速し、日経平均株価は一時3000円以上値下がりしました。
先週末に過去2番目の下げ幅を記録した日経平均株価は先ほど先週末よりも3000円以上値下がりしました
現在はご覧の通りです
2日に発表された雇用統計が市場予想を下回ったことなどから、
アメリカの景気が今後後退するとの懸念が強まっていることが要因です。
東京為替市場の演奏場は先ほど一時1ドル142円台を付け、
今年1月以来およそ7ヶ月ぶりの水準となっています。
日銀が金融政策決定会合で追加の利上げを発表して以降、
円高ドル安が続く中、午後になって円高がさらに加速しています。
“円相場”が“演奏場”となっている箇所はありますが、概ね文字起こしができているようです。
また以下のように文字起こしする時の引数に「task=“translate”」を付加すると英語に翻訳してくれます。
(残念ながら英語から日本語にはできませんが。)
result = model.transcribe(source_file, language=‘ja’,task=“translate” )
上と同じニュースを翻訳させると以下のようになりました。
root@7a49a1206d85:/src# python3 main.py
model load start
model load end
Due to the concern that the US economy will fall, the market entered the afternoon and the price of stocks and yen increased further, and the average daily stock price fell more than 3,000 yen at one time.
The average daily stock price recorded a second-lowest last weekend fell more than 3,000 yen than last weekend.
As you can see now.
The fact that the employment statistics announced on the 2nd have been lower than expected is the cause of the concern that the US economy will be
The performance of the Tokyo Kawase Market has been at a level of about 7 months since January this year, with a price of $1.142 at the time.
After the Japanese dollar announced additional revenues at the financial policy meeting,
As the yen and dollar prices continue, the yen and dollar prices are accelerating in the afternoon.
”株安と円高がさらに加速”が” the price of stocks and yen increased further”のように違うのでは?と言う箇所もありますが、だいたいは英訳はできているように見えます。
さいごに
2回にわたってWhisperを使用した文字起こしの記事を書いてみましたが、いかがでしたでしょうか?
思っていたより簡単に文字起こしができるんだっと思っていただければ幸いです。
前述のようにJETSONには、Whisper以外にもさまざまな生成AIの環境が用意されていますので、またの機会に別の生成AIについても紹介できればと思っております。
また、弊社ではADVANTECH社のJETSONモジュールを搭載した製品を取り扱っていますので、今回の記事をみて少しでもJETSONに興味を持ったり、ふれてみたいと思われましたら、ご気楽にご相談いただければと思っております。
関連製品


関連記事

参考文献
- Jetson Generative AI Lab:https://www.jetson-ai-lab.com/index.html
- jetson-containers:https://github.com/dusty-nv/jetson-containers
- Whisper:https://github.com/openai/whisper
更新履歴
2024/08/20 新規作成